Building a Node.js CLI Scraping Tool (Picky-Scrape)
Links
Motivation
I've been rebuilding a new site for my old school in React.js over the last few months. For the most part it's beeen interesting work. It involved building a CMS with a firebase backend for managing the school's archive photos and a client side image resizer using React and the HTML5 canvas which was fun. But now it comes to the boring part of the project: copying their existing page content over to the new site.
I could do this manually by inspecting their site and grabbing parts that I want to transfer over, but that would leave me with a load of annoying wordpress classes and ids in the html and would not be much craic. Surely I can do better than this! A few weeks dragged on as I avoided the task. But then enough was enough, why not build a tool to do this for me! I decided to build a simple Node.js CLI tool (as an npm module) for scraping and cleaning the HTML from their site.
Steps:
Set up the project structure
Defining paramaters with bin/global.js
Loading/parsing the HTML and writing to file with lib/index.js
(1) Set up project structure
First thing I did was define the package.json file, the three dependencies used in picky scrape are request for making request for the HTML of page, cheerio which is an implementation of JQuery, that will allow us to use JQuery selectors to parse the response and grab the parts we want, and also figlet for display a nice program message when starting the tool!
{
"name": "picky-scrape",
"version": "0.0.1",
"description": "Node.js CLI program for picky part of a site, extracting plain html and writing it to file",
"author": "bbsmithy",
"dependencies": {
"cheerio": "0.22.0",
"figlet": "^1.2.1",
"request": "2.88.0"
},
"main": "./lib/index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"license": "MIT",
"preferGlobal": true,
"bin": {
"picky-scrape": "./bin/global.js"
}
}
bin/global.js will be picky-scrape's entry file and will handle the parameters we pass to it lib/index.js will handle loading the html with request, parsing the response with cheerio and writing to file with nodes filesystem module.
(2) Defining parameters with bin/global.js
bin/global.js is defined in the package.json as the entry file with bin: {picky-scrape: 'bin/global.js'}. So (if picky-scrape is installed globally) when we call picky-scrape from the command line we are calling this file and we can pass params to it.
#!/usr/bin/env node
// Delete the 0 and 1 argument (node and script.js)
var args = process.argv.splice(process.execArgv.length + 2);
// Retrieve the first argument
var URL = args[0];
var SELECTOR = args[1];
var ELEMENT_INDEX = args[2];
var FILE_OUTPUT = args[3];
var pickyScrape = require("../lib/index.js");
pickyScrape.start(URL, SELECTOR, ELEMENT_INDEX, FILE_OUTPUT);
URL: page we want to scrape SELECTOR: class name, id, or element we want to extract the contents from. ELEMENT_INDEX: the index of the found items matching the selector, so if we want the contents of the 3rd .article found on page we can call: picky-scrape [URL] .article 2 [FILE_OUTPUT] FILE_OUPUT: this is the file we will write to with the parsed HTML We then call the lib/index.js start function using these parameters
(3) Loading/parsing the HTML and writing to file
const cheerio = require("cheerio");
const request = require("request");
const figlet = require("figlet");
const fs = require("fs");
function start(URL, SELECTOR, ELEMENT_INDEX = 0, OUTPUT) {
figlet("PickyScrape", function(err, data) {
if (err) {
console.log("Something went wrong...");
console.dir(err);
return;
}
console.log(data);
});
request(URL, (error, response, html) => {
if (!error && response.statusCode === 200) {
const $ = cheerio.load(html);
const resultHTML = $(SELECTOR)
.eq(ELEMENT_INDEX)
.html();
if (resultHTML) {
const plainHTML = removeAttributes(resultHTML);
if (OUTPUT) {
writeToFile(OUTPUT, plainHTML);
} else {
console.log(plainHTML);
}
} else {
console.log(
`No results found for selector [${SELECTOR}] with position [${ELEMENT_INDEX}]`
);
}
} else {
console.log(error);
}
});
}
function removeAttributes(html, callback) {
const cheerioFilter = cheerio.load(html);
cheerioFilter("*").each(function() {
this.attribs = {};
});
return cheerioFilter.html().replace(/\s\s+/g, "");
}
function writeToFile(OUTPUT, html) {
fs.writeFile(OUTPUT, html, function(err) {
if (err) throw err;
console.log(`Results written to ${OUTPUT}`);
});
}
module.exports = {
start
};
The start function is called from bin/global.js, first we output a nice message with figlet. img(src="../img/picky-scrape-terminal-output.png") Then we send a request for the page passed by the user. And load the response if it succeeds into cheerio for parsing:
const $ = cheerio.load(html);
From there we can select the part of the html we want to extarct based off of user input:
const resultHTML = $(SELECTOR)
.eq(ELEMENT_INDEX)
.html();
If the selection works we remove attributes and whitespace from that html with removeAttributes function so we left with just the plain html.
function removeAttributes(html, callback) {
const cheerioFilter = cheerio.load(html);
cheerioFilter("*").each(function() {
this.attribs = {};
});
return cheerioFilter.html().replace(/\s\s+/g, "");
}
After that we can write to file with writeToFile function (if the user specified), otherwise we just console.log(resultHTML)
function writeToFile(OUTPUT, html) {
fs.writeFile(OUTPUT, html, function(err) {
if (err) throw err;
console.log(`Results written to ${OUTPUT}`);
});
}
Scraping the school's site
I'm going to scrape my old schools site for an example on how to use picky-scrape. First we have to find the class or id that contains the content we want to scrape, we want to grab the text content in the middle of the screen.
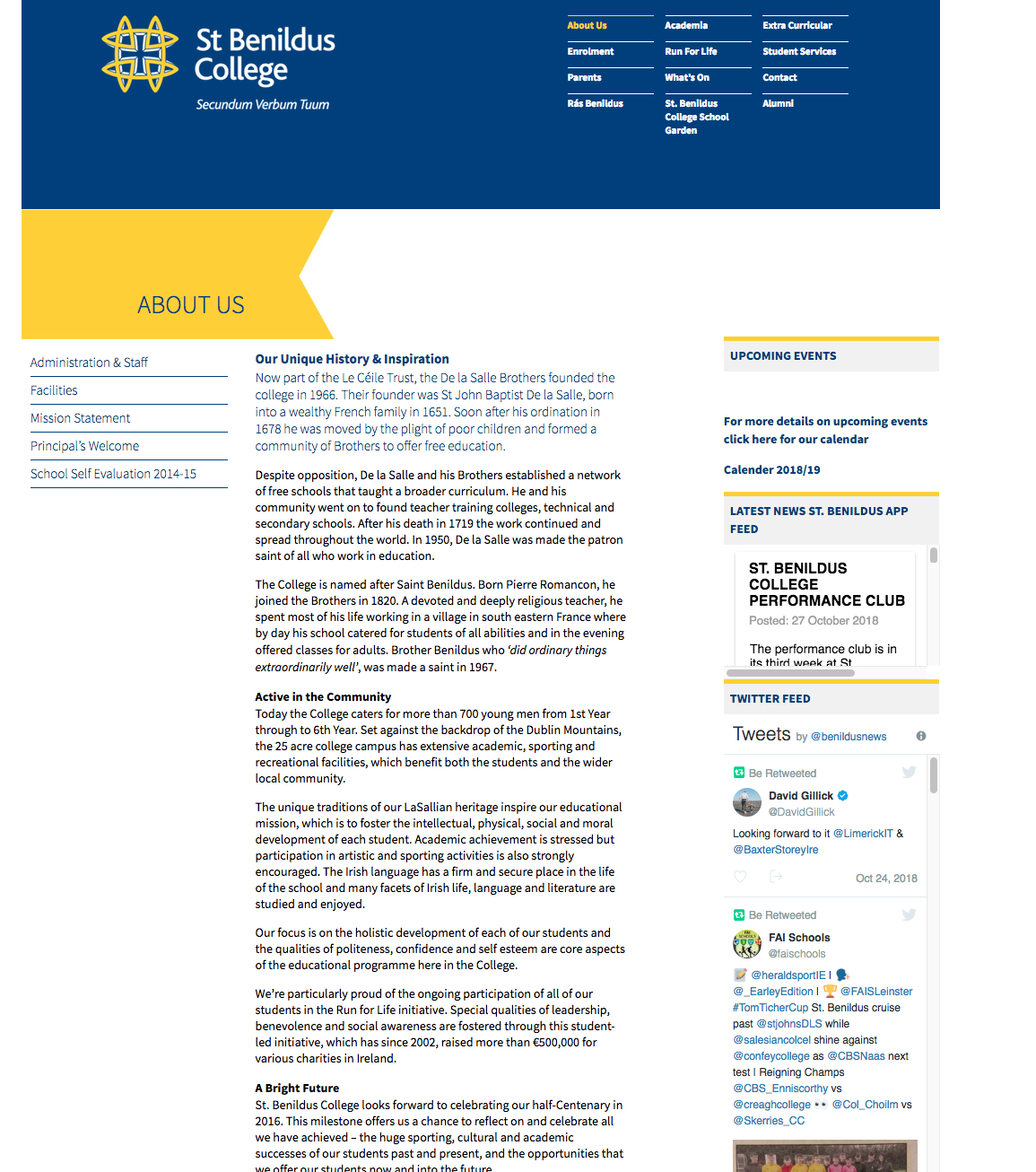
A quick inspect element will show that the class we're looking for is .sb3-sb6
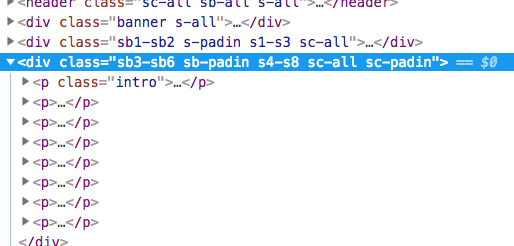
We can then run our scrape:
picky-scrape http://www.stbenilduscollege.com/about-us/ .sb3-sb6 0 site-about-us.html
This will write our plain html form .sb3-sb6 to site-about-us.html, if we open site-about-us.html we get the plain html output:
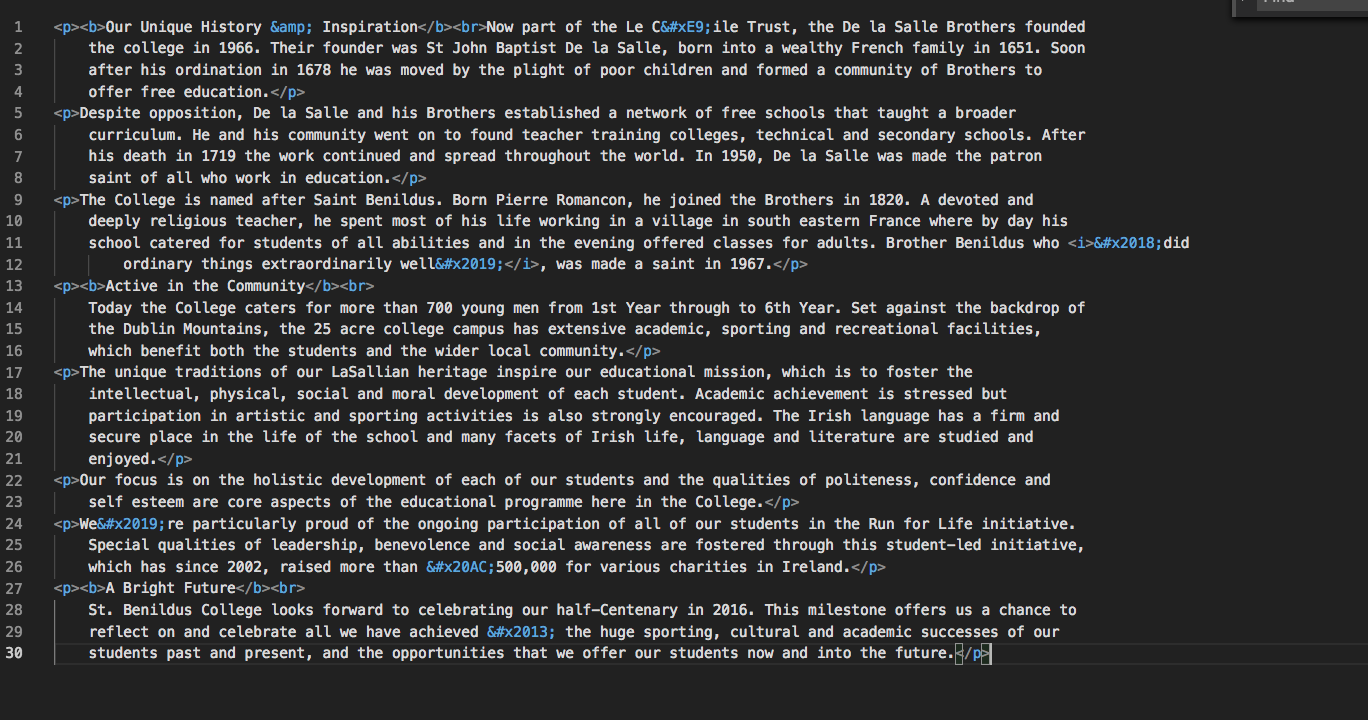
Improvements
To improve picky-scraper we could make sure that the removeAttributes function does not remove src's from images at the moment it removes all attributes
Conclusion
I hope this tool/post helps anyone doing similar website content transfers, or just gives people an idea on how to scrape sites with node.js
If you want to use this package you can install it with:
$ npm install -g picky-scrape
Thanks for reading!